안녕하세요, 오늘은 지난 시간에 설명한 데이터 프레임을 이용하여 데이터를 분석하고 가공하는 방법에 대해 알아보도록 하겠습니다.
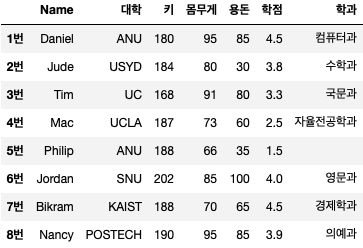
이것은 오늘 사용할 예제 데이터입니다.
import pandas as pd
example_data = {'Name': ('Daniel', 'Jude', 'Tim', 'Mac', 'Philip', 'Jordan', 'Bikram', 'Nancy'),
'대학': ('ANU', 'USYD', 'UC', 'UCLA', 'ANU', 'SNU', 'KAIST', 'POSTECH'),
'키': (180, 184, 168, 187, 188, 202, 188, 190),
'몸무게': (95, 80, 91, 73, 66, 85, 70, 95),
'용돈': (85, 30, 80, 60, 35, 100, 65, 85),
'학점': (4.5, 3.8, 3.3, 2.5, 1.5, 4.0, 4.5, 3.9),
'학과': ('컴퓨터과', '수학과', '국문과', '자율전공학과', '', '영문과', '경제학과', '의예과')}
df = pd.DataFrame(example_data, index = ('1번','2번','3번','4번','5번','6번','7번','8번'))
1. 인덱스 접근 및 조작
ㅏ. 인덱스 확인
데이터 프레임의 인덱스 정보를 확인할 때 사용합니다.
df.index# Index(('1번', '2번', '3번', '4번', '5번', '6번', '7번', '8번'), dtype="object")다음과 같이 인덱스 번호 목록을 포함하는 객체를 반환합니다.
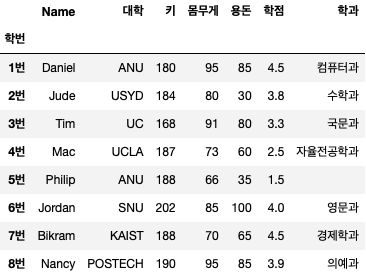
비. 인덱스 이름 설정
데이터 프레임 인덱스 열의 이름을 설정하고자 할 때 사용합니다.
df.index.name="학번"위의 코드를 실행하면 첫 번째 데이터 프레임과 달리 인덱스 컬럼에 “학번”이라는 이름이 부여된다.
씨. 인덱스 초기화
지정한 인덱스를 초기화하고 Pandas에서 자동으로 지정한 인덱스를 사용하고자 할 때 사용합니다.
df.reset_index() # 1
df.reset_index(drop=True) # 2
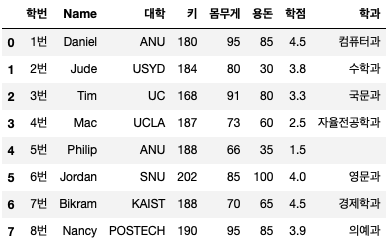
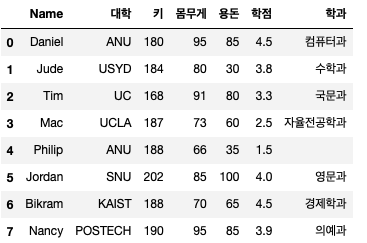
두 코드 모두 pandas는 인덱스를 0부터 자동으로 재설정하지만 drop 속성을 True로 설정하면 이전에 사용했던 인덱스 열이 삭제됩니다.
단, 인덱스 초기화 시 주의사항이 있습니다. 1번과 2번 코드를 실행하면 위의 그림과 같이 결과가 출력되지만 다시 원본 데이터 프레임 “df”를 출력하면 아래와 같이 결과가 반환된다.
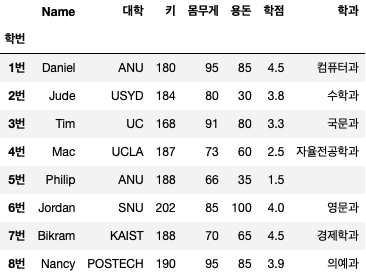
reset_index()는 실제 데이터 프레임에 적용되지 않습니다. 이를 적용하려면 다음 코드를 추가해야 합니다.
df.reset_index(inplace = True) # 1'
# df = df.reset_index()
df.reset_index(drop = True, inplace = True) # 2'
#df = df.reset_index(drop = True)#1’과 #2’는 각각 #1과 #2와 동일하게 작동하지만 실제 원본 데이터에 적용됩니다! (각각 주석 처리된 부분과 동일하게 동작합니다.)
디. 색인 설정
별도의 데이터 입력 없이 데이터 프레임의 컬럼을 기준으로 인덱스를 설정할 수 있습니다.
df.set_index('키')
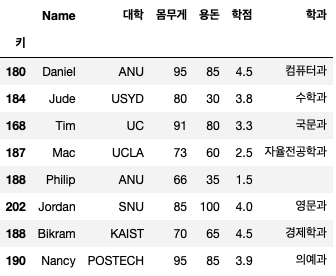
이렇게 데이터 프레임의 인덱스를 설정할 수 있지만, 초기화할 때와 같이 데이터 프레임에 직접 적용하려면 inplace 속성 값을 True로 설정해야 적용됩니다.
이자형. 색인별로 데이터 정렬
인덱스를 기준으로 데이터 프레임의 데이터를 정렬할 수 있습니다.
df.sort_index() # 오름차순 기본값 : ascending = True
df.sort_index(ascending = False) # 내림차순
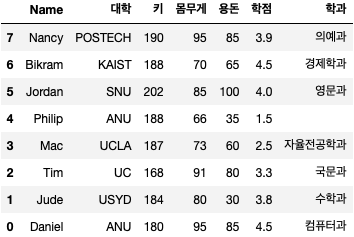
정렬된 결과를 원본 데이터 프레임에 반영하려면 inplace 값을 True로 설정해야 합니다!
2. 데이터 선택
ㅏ. 열에 저장된 값 확인
데이터 프레임의 열을 통해 값을 가져오고 보는 방법을 살펴보겠습니다.
df('Name') # df('컬럼이름')
# 결과
0 Daniel
1 Jude
2 Tim
3 Mac
4 Philip
5 Jordan
6 Bikram
7 Nancydf(‘Name’)를 사용하면 인덱스와 함께 Name 열의 모든 값을 가져올 수 있습니다. Name이 아니더라도 예제 데이터 프레임의 ‘University’, ‘Height’, ‘Weight’, ‘Pocket money’, ‘Grades’, ‘Department’ 열을 ‘Name’ 대신 입력할 수도 있습니다. 해당 열의 데이터를 가져옵니다. .
df(('Name','학과'))또한 이와 같이 리스트 형태로 칼럼을 입력하면 해당 칼럼 값의 데이터를 한번에 불러오는 것도 가능하다.
비. 열 선택
df.columns
# 결과
Index(('Name', '대학', '키', '몸무게', '용돈', '학점', '학과'), dtype="object")
df.columns(2)
# 결과
'키'‘.columns’를 통해 리스트 형태로 데이터 프레임의 컬럼명을 확인할 수 있으며, 일반 파이썬 리스트처럼 숫자 인덱스로 접근하여 특정 값만을 획득하는 것도 가능하다.
이렇게 구한 값으로 ‘2 – a’에서 컬럼에 저장된 데이터를 구하는 것도 가능하다.
df(df.columns(0))
# 결과
0 Daniel
1 Jude
2 Tim
3 Mac
4 Philip
5 Jordan
6 Bikram
7 Nancy그런 점에서 위의 코드는 ‘2-a’ 예제와 동일하게 동작합니다.
씨. 데이터 슬라이싱
지난 시간에 데이터 프레임은 데이터를 2차원으로 저장할 수 있는 구조라고 말씀드렸습니다.
따라서 2차원 리스트에 접근하듯이 접근이 가능하다.
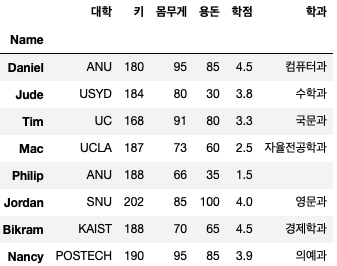
df(0:3) # 1 - 0번 row ~ 2번 row 반환
df(('Name','대학'))(0:3) # 2 - 'Name' 과 '대학' 컬럼의 0번 row ~ 2번 row 반환
2D 리스트와의 한 가지 차이점은 2D 리스트에서 1번처럼 접근하면 0열부터 2열까지의 데이터가 나와야 한다고 생각할 수 있는데 2D 리스트와는 조금 다르게 동작한다.
디. loc을 통한 데이터 선택
이 부분은 조금 복잡할 수 있습니다.
‘loc’은 데이터 프레임의 속성 중 하나로 해당 데이터를 인덱스 값으로 찾을 수 있도록 도와줍니다. 인덱스 값 외에도 부울 목록도 인수로 받을 수 있지만 나중에 소개하겠습니다.
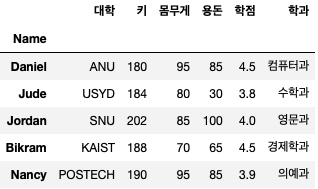
이제부터는 ‘Name’ 열을 인덱스로 하는 데이터 프레임을 사용하겠습니다.
# 기본형 : df.loc(index, column)
df.loc('Jude') # Jude row에 저장된 모든 컬럼의 데이터를 가져옵니다.
df.loc('Jude', '학과') # Jude row의 학과컬럼의 데이터를 불러옵니다.
df.loc('Jude', ('학과', '용돈')) # Jude row의 학과와 용돈컬럼의 데이터를 불러옵니다.
df.loc('Jude', '용돈':'학과') # Jude row의 용돈컬럼부터 학과 컬럼까지의 데이터를 불러옵니다.
df.loc(('Jude','Jordan')) # Jude 와 Jordan row에 저장된 모든 컬럼의 데이터를 불러옵니다.
df.loc(('Jude','Jordan'), '대학') # Jude 와 Jordan row의 대학컬럼의 데이터를 불러옵니다.
df.loc(('Jude','Jordan'), ('대학', '용돈')) # Jude 와 Jordan row의 대학과 용돈컬럼의 데이터를 불러 옵니다.
df.loc('Jude':'Jordan') # Jude ~ Jordan 까지의 row 의 모든컬럼의 데이터를 불러옵니다.많은 예시가 있지만 기본적으로 loc의 인덱스와 컬럼에 여러 데이터를 전달할 때 리스트 형태로 전달할 수 있다는 점만 기억하시고 상황과 편의에 따라 사용하시면 됩니다!
이자형. iloc을 통한 데이터 선택
loc이 인덱스 값을 기준으로 동작한다면 iloc은 숫자 데이터 구조를 인자로 받아 동작한다.
여기서 숫자 데이터 구조는 Pandas가 데이터 프레임의 각 행에 대해 기본적으로 설정하는 인덱스 번호로 생각하는 것이 좋습니다.
loc과 유사하게 동작하므로 간단히 설명하겠습니다.
# 기본형 df.iloc(row_number, column_number)
df.iloc(5) # 5번째 row의 모든 컬럼에 저장된 데이터를 불러옵니다. (0부터 카운트)
df.iloc(5, (1:4)) # 5번째 row의 1번~3번 컬럼의 데이터를 불러옵니다. (행과열모두 0부터 카운트)
# row_number 와 column_number 는 int, (int1, int2), (int1 : int2)의 형식으로 전달할 수 있습니다.
# column_number 는 생략이 가능합니다.
에프. 조건을 통한 데이터 선택
특정 조건에 맞는 데이터만 선택하고 싶다면 원하는 조건을 찾아서 데이터 프레임에 적용하면 데이터만 불러올 수 있습니다.
예를 통해 살펴보겠습니다. 학점이 평균 3.5 이상인 사람을 찾으려면 원하는 조건에 다음 코드를 입력하면 ‘#result’와 ‘boolean’ 목록이 반환됩니다.
df('학점') >= 3.5
# 결과
Name
Daniel True
Jude True
Tim False
Mac False
Philip False
Jordan True
Bikram True
Nancy True데이터 프레임이 이러한 부울 유형 목록을 인수로 받으면 값이 True인 행에 대해서만 데이터가 로드됩니다.
# 1
df(df('학점') >= 3.5)
# 2
condition = df('학점') >= 3.5
df(condition)
# 3
df.loc((df('학점') >= 3.5))
# 4
df.loc(condition)
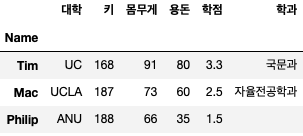
조건을 넘길 때도 위와 같은 방법으로 넘길 수 있습니다. 또한 조건 앞에 ‘~’를 추가하면 조건을 만족하지 않는 값도 구할 수 있다. 다음 코드는 조건 앞에 ‘~’를 추가하여 각 부울 값의 반대(음수) 값을 가지고 있어 GPA가 3.5 미만인 학생을 찾는 코드입니다. #3,4는 위에서 언급한 loc 속성에 boolean list를 인자로 주는 경우이다.
df(~(df('학점') >= 3.5)) # 1
df(~condtion) # 2
이러한 단일 조건 및 부정 조건 외에도 여러 조건을 사용하여 원하는 데이터를 선택할 수도 있습니다. 파이썬의 기본 논리 연산자
‘|’ (OR)과 ‘&'(AND)는 논리 연산을 통해 조건을 가져올 수 있습니다.
or_condition = (condition1) | (condition2) # 논리합
and_condition = (condtion1) & (condition2) # 논리곱동일한 방식을 데이터 프레임에 단일 조건으로 적용하여 데이터를 로드할 수 있지만, 한 가지 주의할 점은 전체 조건을 ‘(‘ 및 ‘)’로 묶는 것이 아니라 각 조건문을 괄호로 묶어야 한다는 것입니다.
오늘은 판다스 라이브러리를 통해 데이터 프레임에서 원하는 데이터를 찾는 다양한 방법에 대해 알아보았습니다.